我们在很多项目开发中 ,可能会用到多个标签查询一条数据,譬如一条数据有多个用户维护,需要我们按用户id 查询出所属的数据信息,又如 一些文章我们添加了tag标记,我需要把这篇文章相关的其他文章匹配出来,这个时候们就需要用到标签查询,而在这里我主要介绍几种标签查询的比较。
首先我以一个例子来描述这个数据结构的问题。
测试版本:mysql 5.7 deepin 15.6
测试软件: Mysql Workbench
这里我以一个 product 表,表中可以有多个tag 标记结构如下:
product
id | tags | price
-----+-------+------
1 | 2,3,4 | 300
2 | 3,4,5 | 400
3 | 4,5,6 | 350
我们需要查询 标签 tag 3 的时候找到 id 1 2 的数据,或者 查询 tag 5 的时候找到 id 2 3 的数据。
这个时候聪明的小朋友们可能就会立马想到 一个关键字 FIND_IN_SET ,是的 这里也会讲到 FIND_IN_SET。
但是有些朋友说 这样不是应该用一个 关联关系表来描述吗,也就是说有如下这个结构的数据出现:
关联关系表 prodoct_tags 就由此被引进了项目。
product_tags
id | tagId | productId
---+-------+----------
1 | 2 | 1
2 | 3 | 1
3 | 3 | 2
4 | 4 | 1
5 | 4 | 2
6 | 4 | 3
7 | 5 | 2
8 | 5 | 3
9 | 6 | 3这里 可以使用两种方式进行关联,如下:
SELECT * FROM product A where EXISTS(SELECT 1 FROM product_tags WHERE tagId=1000 AND productId=A.Id);
SELECT * FROM product A LEFT JOIN product_tags ON tagId=1000 AND productId=A.Id;
本文也会讨论比较这种方式,但是数据如果很大,比如 100万数据,反正我是跑了10分钟 还没结束自己手动结束了,聪明的同学可能又会说 干嘛不加索引,是的 应该加一个 tag_pro_index 索引,也就是做一个组合索引 tagId,productId 一起的组合索引。
为了大家能够自己演示,我已经准备好了生成 prodcut 的代码。
生成 100万条数据 代码如下:
请使用命令行模式运行(这样你可以实时看到进度)
<?php
ini_set("max_execution_time", "300");
ini_set('memory_limit', '256M');
$sqli = new mysqli('127.0.0.1', 'root', '123456', 'mytest1', 3306);
$sqli->query("SET NAMES utf8");
$sqli->query('start transaction');
ob_implicit_flush(1);
//生成产品表
$sqli->query('CREATE TABLE IF NOT EXISTS `product` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`tags` varchar(255) DEFAULT \'\',
`price` int(11) DEFAULT NULL,
`addtime` datetime DEFAULT NULL,
`updatetime` datetime DEFAULT NULL,
FULLTEXT (tags),
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
');
//设置生成大小
$size = 1000000;
echo '---生成产品数据' . PHP_EOL;
$stmt = $sqli->prepare('INSERT INTO product(`tags`,`price`,`addtime`,`updatetime`) VALUE (?,?,?,?)');
$stmt->bind_param("siss", $t2name, $price, $addtime, $updatetime);
for ($i = 0; $i < $size; $i++) {
// echo $i . PHP_EOL;
if ($i % 10000 == 0) {
if ($i != 0) {
$sqli->query('commit');
}
$sqli->query('begin');
$p = floor($i * 100 / $size);
echo $i . '/' . $size . '---' . $p . '%' . PHP_EOL;
}
$tags = [];
$tagLen = mt_rand(3, 10);
for ($j = 0; $j < $tagLen; $j++) {
$tags[] = mt_rand(1, 10000);
}
$t2name = join(',', $tags);
$price = mt_rand(1, 10000);
$addtime = date('Y-m-d H:i:s', mt_rand(time() - 86400 * 365, time()));
$updatetime = date('Y-m-d H:i:s', mt_rand(time() - 86400 * 365, time()));
$stmt->execute();
}
$sqli->query('commit');
$stmt->close();
echo '完成' . PHP_EOL;
如果你也想比较 使用关联表的,我也准备了一份生成关联表的php 代码:
需要先生成 product 表:
<?php
ini_set("max_execution_time", "300");
ini_set('memory_limit', '256M');
$sqli = new mysqli('127.0.0.1', 'root', '123456', 'mytest1', 3306);
$sqli->query("SET NAMES utf8");
$sqli->query('start transaction');
//产品对应的标签表
$sqli->query('CREATE TABLE IF NOT EXISTS `product_tags` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`tagId` int(11) NOT NULL DEFAULT \'0\',
`productId` int(11) NOT NULL DEFAULT \'0\',
PRIMARY KEY (`id`),
KEY `tag_pro_index` (`tagId`,`productId`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
');
echo '---生成产品标签数据' . PHP_EOL;
$stmt = $sqli->prepare('INSERT INTO product_tags(`tagId`,`productId`) VALUE (?,?)');
$stmt->bind_param("ii", $tagId, $productId);
$result = $sqli->query('SELECT COUNT(*) FROM product');
$count = $result->fetch_row()[0];
$pages = ceil($count / 5000);
for ($idx = 0; $idx <= $pages; $idx++) {
echo $idx . PHP_EOL;
$sqli->query('begin');
$p = floor($idx * 100 / $pages);
echo $idx . '/' . $pages . '---' . $p . '%' . PHP_EOL;
$start = $idx * 5000;
$prolist = $sqli->query('SELECT id,tags FROM product limit ' . $start . ',5000')->fetch_all(MYSQLI_ASSOC);
//print_r($prolist);
foreach ($prolist as $item) {
$productId = $item['id'];
$tags = explode(',', $item['tags']);
foreach ($tags as $tag) {
$tagId = intval($tag);
$stmt->execute();
}
}
$sqli->query('commit');
}
$stmt->close();
echo '---生成产品标签数据' . PHP_EOL;
数据生成可能需要一些时间,大概是5-10分钟这样,如果你机器够快(主要是硬盘 SSD )
下面 我们在真实测试一下
1 使用 FIND_IN_SET
代码:
SELECT * FROM product WHERE FIND_IN_SET('1000',tags) ;
-- 耗时 0.061秒 我机器比较快吧,还能接受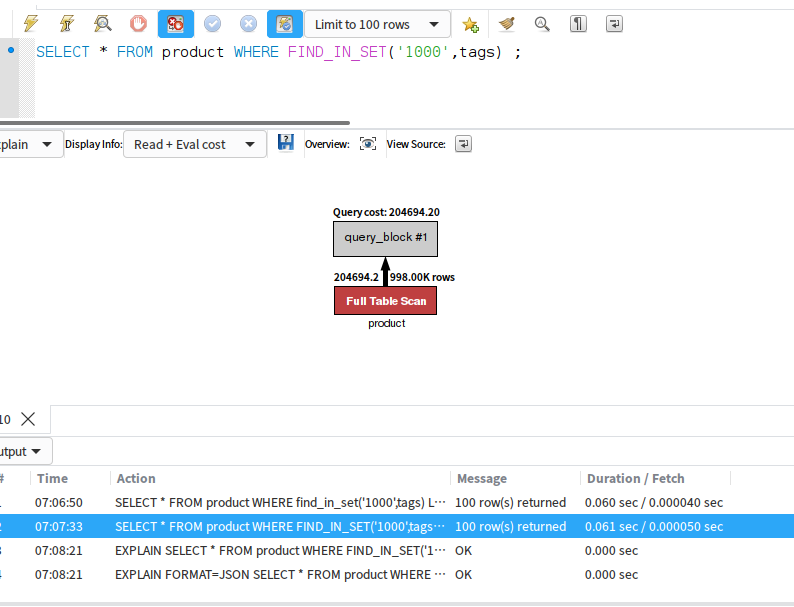
因为没有办法用到索引,所有全表扫描,但是速度不错 0.061 就搞定了。
还有两种方式可以查询,比如 正则查询 和 like 查询:
SELECT * FROM product WHERE tags REGEXP '(^|,)1000(,|$)';
--耗时 0.057s
SELECT * FROM product WHERE CONCAT(',',tags,',') LIKE '%,1000,%';
--耗时 0.098s和 FIND_IN_SET 也相差不远。
这个时候可能有些朋友迫不及待的需要我测试一下 链表查询的速度了,这个不测没有索引的情况了,就测 product_tags 在添加了组合索引 tag_product_index 的情况。
虽然 product_tags 已经使用了索引,但是 product 表还是依然全表扫描,而且得出的时间 0.644秒 比 like 还要差。
在看一下 left join
SELECT * FROM product A LEFT JOIN product_tags ON tagId=5201 AND productId=A.Id;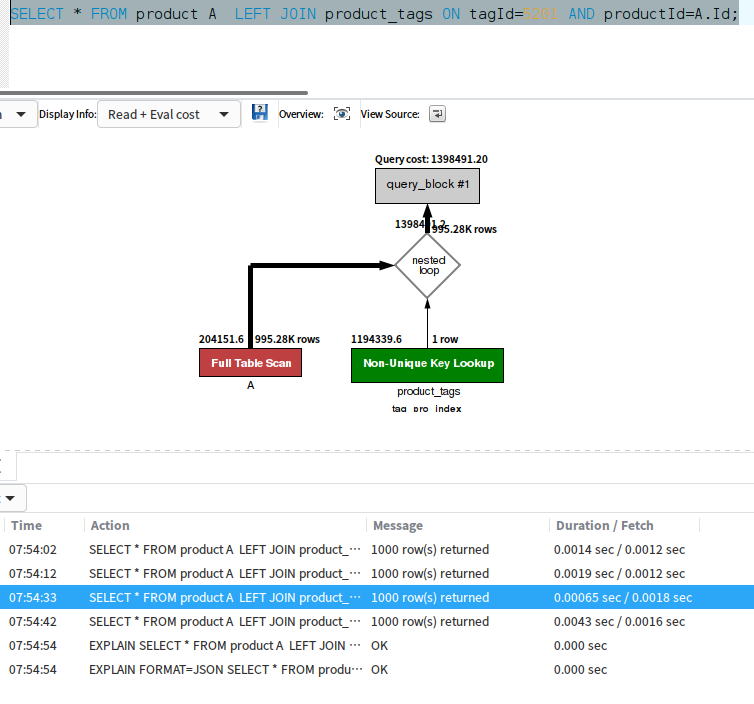
这个结果还是很不错的,而且如果重复查询 时间会更少,第一次查的时候大概 0.0014 秒 -0.0043秒之间。第2次查 就只有 0.00065秒了。
不过 product 还是“全表扫表”了,这里用了引号的全表扫描,是因为下文会说道。
那么 除了上面两种方法 还有没有别的方法呢?
细心的朋友可能会发现 我生成 product 的时候使tags 使用了FullText 索引,是的我们这里要讲另外一种方法是利用 FullText 的,如果你刚刚已经生成了数据,没有将 my.ini 的两个配置项该成如下:
[mysqld]
ft_min_word_len=1
innodb_ft_min_token_size=1因为我们只是用全文索引来满足我们标签查询,所以分词最小长度需要设置为 1,innodb_ft_min_token_size 是 innodb 的设置。
然后就是重启mysql 服务,还得修复一下原来已经生成的索引。
执行SQL查询语句
REPAIR TABLE product QUICK;
OK,这个时候我们可以测试一下使用 全文索引来检索标签查询的效果了。
SELECT * FROM product WHERE MATCH(tags) AGAINST('1000');
使用全文索引 大概保持在 0.0016 左右,和 left join 的效果差不多,不过不在全表扫描了。
为了更深入的比较 全文索引 和 left join 我特地把数据提升了一倍,product 200W product_tags 1200万。
SELECT * FROM product A LEFT JOIN product_tags ON tagId=1000 AND productId=A.Id;
--- 第1次 0.0017 左右
--- 第2次 0.00070s 相同sql 语句而 :
SELECT * FROM product WHERE MATCH(tags) AGAINST('1000');
--- 耗时 0.0021s 而使用另外两个链表方式: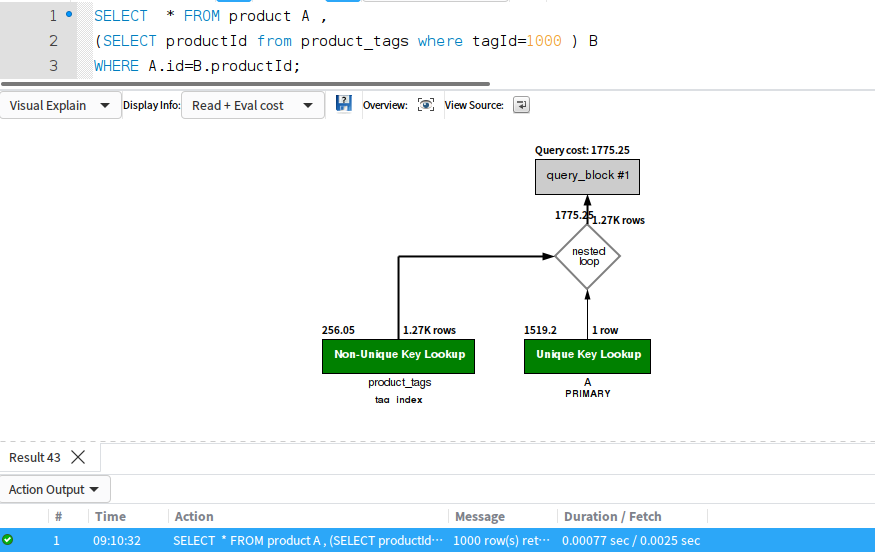
SELECT * FROM product A ,
(SELECT DISTINCT productId from product_tags where tagId=1000 ) B
WHERE A.id=B.productId;
-- 第1次 0.0012s 左右
-- 第2次 0.00077s
使用 in 查找
SELECT * FROM product WHERE id In (SELECT DISTINCT productId FROM product_tags WHERE tagId=1000);
---第1次 0.0017-0.0021
---第2次 0.00078秒
最后在测试一下原来的 FIND_IN_SET 正则和 like
SELECT * FROM product WHERE FIND_IN_SET('1000',tags) ;
-- 耗时 0.126s
SELECT * FROM product WHERE tags REGEXP '(^|,)1000(,|$)';
--耗时 0.117s
SELECT * FROM product WHERE CONCAT(',',tags,',') LIKE '%,1000,%';
--耗时 0.182s基本成线性增长。
比较完以后 发现 left join 其实和 后面两种方式基本一样,所以虽然是“全表扫描”,但是其实mysql 在内部做了相应的优化,是先从 product_tags 找到 productId 然后在从id 中 使用主键 到 product 对应的数据的。其实和 后面这句 IN 的语句极为相识,至于 第2次查找会更快 可能是因为mysql 对一些中间结果做了相应的缓存优化,或者是对索引数据部分做了内存优化。而全文索引中 可能没有相应的优化。
本文为原创文章,未经允许不可转载,请尊重作者劳动成果。